Traditional RAG vs Agentic RAG

Thumbnail Credit
What is RAG?
Retrieval-Augmented Generation combines the power of large language models with external knowledge retrieval systems. Instead of relying solely on pre-trained knowledge, RAG systems can access up-to-date information from various sources, making them more accurate and current for knowledge-intensive tasks.
Traditional RAG Architecture

Core Components
Traditional RAG follows a straightforward, linear pipeline with four main components:
1. Knowledge Base
- Contains structured or unstructured documents
- Pre-processed and indexed for efficient retrieval
- Static knowledge repository
2. Embedding Model
- Converts queries and documents into vector representations
- Enables semantic similarity matching
- Typically uses models like BERT, Sentence-BERT, or specialized embedding models
3. Vector Store
- Stores document embeddings for fast retrieval
- Supports similarity search operations
- Common implementations include Pinecone, Weaviate, Qdrant, or FAISS
4. Large Language Model (LLM)
- Generates responses based on retrieved context
- Combines retrieved information with query understanding
- Examples include GPT-4, Claude, or domain-specific models
Traditional RAG Workflow
The Traditional RAG process follows these sequential steps:
- Query Processing: User submits a query
- Encoding: Query is converted to embeddings using the embedding model
- Similarity Search: Vector store performs semantic search to find relevant chunks
- Context Retrieval: Most similar documents/chunks are retrieved
- Response Generation: LLM generates answer using query + retrieved context
- Response Delivery: Final answer is returned to the user
Advantages of Traditional RAG
- Simplicity: Straightforward architecture that's easy to understand and implement
- Predictable Performance: Linear workflow with consistent response patterns
- Lower Latency: Direct path from query to response without complex decision-making
- Cost-Effective: Minimal computational overhead beyond core retrieval and generation
- Debugging Friendly: Easy to trace issues through the linear pipeline
Limitations of Traditional RAG
- Limited Adaptability: Cannot adjust retrieval strategy based on query complexity
- Single Retrieval Pass: May miss relevant information that requires multiple searches
- No Tool Integration: Cannot leverage external APIs or specialized tools
- Context Window Constraints: Fixed approach to handling large result sets
- Query Type Blindness: Treats all queries identically regardless of their nature
Agentic RAG Architecture

Core Innovation: The Aggregator Agent
Agentic RAG introduces an intelligent orchestration layer called the Aggregator Agent that transforms the rigid pipeline into a flexible, adaptive system.
Key Capabilities of the Aggregator Agent:
- Dynamic Tool Selection: Chooses appropriate tools based on query analysis
- Multi-Step Reasoning: Can perform complex, multi-hop information retrieval
- Context Awareness: Adapts strategy based on intermediate results
- Tool Orchestration: Coordinates multiple tools and data sources
- Result Synthesis: Intelligently combines information from various sources
Enhanced Components
1. Tool Ecosystem
- Multiple specialized vector search tools (Vector Search Tool A, B, etc.)
- External APIs and data sources
- Specialized processing tools for different data types
- Custom tools for domain-specific tasks
2. Intelligent Routing
- Query analysis to determine optimal retrieval strategy
- Dynamic tool selection based on query characteristics
- Adaptive context management
3. Enhanced Vector Search
- Multiple vector stores with different specializations
- Parallel search capabilities across multiple sources
- Advanced similarity search with metadata filtering
Agentic RAG Workflow
The Agentic RAG process involves sophisticated decision-making:
- Query Analysis: Aggregator Agent analyzes query complexity and requirements
- Tool Selection: Agent selects relevant tools from available ecosystem
- Parallel Processing: Multiple tools process query simultaneously or sequentially
- Result Aggregation: Agent combines and synthesizes results from multiple sources
- Iterative Refinement: Agent may perform additional searches based on initial results
- Context Optimization: Intelligent selection and ranking of retrieved information
- Response Generation: LLM generates comprehensive response using optimized context
- Quality Assessment: Agent may validate and refine the final response
Advantages of Agentic RAG
- Adaptive Intelligence: Adjusts retrieval strategy based on query complexity
- Multi-Source Integration: Seamlessly combines information from various sources
- Complex Query Handling: Excels at multi-step reasoning and complex information needs
- Tool Extensibility: Easy to add new tools and capabilities
- Context Optimization: Intelligent management of context windows and information ranking
- Quality Assurance: Built-in mechanisms for result validation and refinement
Potential Challenges of Agentic RAG
- Increased Complexity: More sophisticated architecture requires careful design
- Higher Latency: Decision-making overhead can increase response times
- Cost Considerations: Multiple tool calls and processing steps increase computational costs
- Debugging Complexity: Non-linear workflows can make troubleshooting more challenging
- Agent Reliability: Requires robust agent logic to prevent infinite loops or poor decisions
Comparative Analysis
Performance Characteristics
| Aspect | Traditional RAG | Agentic RAG |
|---|---|---|
| Query Complexity | Simple to moderate | Simple to highly complex |
| Response Time | Fast (single pass) | Variable (depends on complexity) |
| Accuracy | Good for straightforward queries | Superior for complex, multi-faceted queries |
| Scalability | High (linear scaling) | Moderate (depends on agent complexity) |
| Maintenance | Low | Moderate to High |
Use Case Suitability
Traditional RAG is ideal for:
- FAQ systems and simple question answering
- Document search and retrieval
- Single-domain knowledge bases
- Applications requiring consistent low latency
- Systems with limited computational resources
- Proof-of-concept and MVP development
Agentic RAG excels in:
- Complex research and analysis tasks
- Multi-domain knowledge integration
- Conversational AI requiring context awareness
- Systems needing external tool integration
- Enterprise applications with diverse data sources
- Advanced AI assistants and expert systems
Implementation Considerations
Choosing Traditional RAG when:
- Query patterns are predictable and straightforward
- Single knowledge source is sufficient
- Response time is critical
- Team has limited ML engineering expertise
- Budget constraints require cost optimization
Choosing Agentic RAG when:
- Queries involve complex reasoning or multi-step processes
- Multiple data sources need integration
- System requires extensibility and tool integration
- Quality and comprehensiveness outweigh speed concerns
- Advanced AI capabilities are business differentiators
Technical Implementation Insights
Traditional RAG Implementation Stack
Frontend → API Gateway → Query Processor → Embedding Service →
Vector Database → LLM Service → Response Formatter → FrontendAgentic RAG Implementation Stack
Frontend → API Gateway → Agent Orchestrator → Tool Selector →
[Multiple Tools in Parallel] → Result Aggregator → Context Optimizer →
LLM Service → Response Validator → FrontendKey Technical Considerations
For Traditional RAG:
- Focus on optimizing embedding quality and vector search performance
- Implement efficient chunk sizing and overlap strategies
- Optimize context window utilization
- Ensure robust error handling in the linear pipeline
For Agentic RAG:
- Design flexible agent decision-making logic
- Implement robust tool registration and management systems
- Create effective result aggregation and ranking algorithms
- Build comprehensive monitoring and observability tools
Implementation Agentic RAG with LLMfy
Define tools
@Tool()
def company_info_search(question: str):
"""Use for general company information."""
# YOUR SIMILARITY SEARCH LOGIC
return context
@Tool()
def legal_info_search(question: str):
"""Use for legal information."""
# YOUR SIMILARITY SEARCH LOGIC
return contextDefine Agentic RAG
from llmfy import (
LLMfy,
START,
END,
LLMfyPipe,
ToolRegistry,
WorkflowState,
tools_node,
BedrockModel,
BedrockConfig,
)
model = "amazon.nova-pro-v1:0"
llm = BedrockModel(
model=model,
config=BedrockConfig(temperature=0.7),
)
SYSTEM_PROMPT = """You are an assistant with access to two retrieval tools:
1) company_info_search — for general company information.
2) legal_info_search — for legal information.
Rules:
- ALWAYS use the relevant tool(s) before answering. If both are relevant, call both.
- If the question is outside these knowledge above, say you only cover company/legal.
- Be concise, specific, and action-oriented. If there are differences across versions/dates, highlight them.
"""
# Initialize framework
ai = LLMfy(llm, system_message=SYSTEM_PROMPT)
tools = [amboja_info_search, portrai_info_search]
# Register tool
ai.register_tool(tools)
# Register to ToolRegistry
tool_registry = ToolRegistry(tools, llm)
# Workflow
workflow = LLMfyPipe(
{
"messages": [],
}
)
async def aggregator_agent(state: WorkflowState) -> dict:
messages = state.get("messages", [])
response = ai.chat(messages)
messages.append(response.messages[-1])
return {"messages": messages, "system": response.messages[0]}
async def node_tools(state: WorkflowState) -> dict:
messages = tools_node(
messages=state.get("messages", []),
registry=tool_registry,
)
return {"messages": messages}
def should_continue(state: WorkflowState) -> str:
messages = state.get("messages", [])
for msg in messages:
print(msg)
last_message = messages[-1]
if last_message.tool_calls:
return "tools"
return END
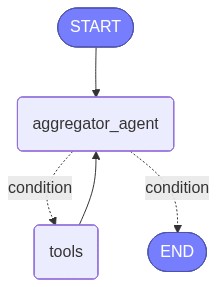
# Add nodes
workflow.add_node("aggregator_agent", aggregator_agent)
workflow.add_node("tools", node_tools)
# Define workflow structure
workflow.add_edge(START, "aggregator_agent")
workflow.add_conditional_edge("aggregator_agent", ["tools", END], should_continue)
workflow.add_edge("tools", "aggregator_agent")
Check workflow agent diagram in Notebooks
from IPython.display import Image, display
# Check diagram
graph_url = workflow.get_diagram_url()
display(Image(url=graph_url))example:
Define Funtion to call agentic RAG
from llmfy import Message, Role
async def call_agentic_rag(question: str):
try:
res = await workflow.execute(
{"messages": [Message(role=Role.USER, content=question)]}
)
messages = res.get("messages", [])
content = messages[-1].content if messages else None
print(messages)
return content
except Exception as e:
raise eTest Call
response = await call_agentic_rag(question="Apa visi dan misi utama perusahaan?")
Output:
Visi:
Menjadi perusahaan terdepan yang memberikan solusi inovatif dan berkelanjutan untuk meningkatkan kualitas hidup masyarakat serta menciptakan nilai tambah bagi seluruh pemangku kepentingan.
Misi:
- Memberikan produk dan layanan berkualitas tinggi yang berfokus pada kebutuhan pelanggan.
- Mengedepankan inovasi dan teknologi untuk mendukung pertumbuhan berkelanjutan.
- Menciptakan lingkungan kerja yang profesional, inklusif, dan mendukung pengembangan karyawan.
- Berkontribusi aktif terhadap pembangunan ekonomi, sosial, dan lingkungan.Conclusion
Both Traditional and Agentic RAG have their place in the modern AI landscape. Traditional RAG provides a solid foundation for straightforward retrieval tasks with its simplicity, predictability, and cost-effectiveness. Agentic RAG, while more complex, offers unprecedented flexibility and capability for handling sophisticated information needs.
The choice between these approaches should be driven by specific use case requirements, technical constraints, and organizational capabilities. Many successful implementations will likely employ hybrid approaches, using traditional RAG for routine queries while leveraging agentic capabilities for complex scenarios.
As the field continues to evolve, understanding both paradigms will be crucial for building effective, scalable AI systems that can truly augment human intelligence and decision-making capabilities.