Computer Adaptive Testing (CAT) Theory
Thumbnail Credit
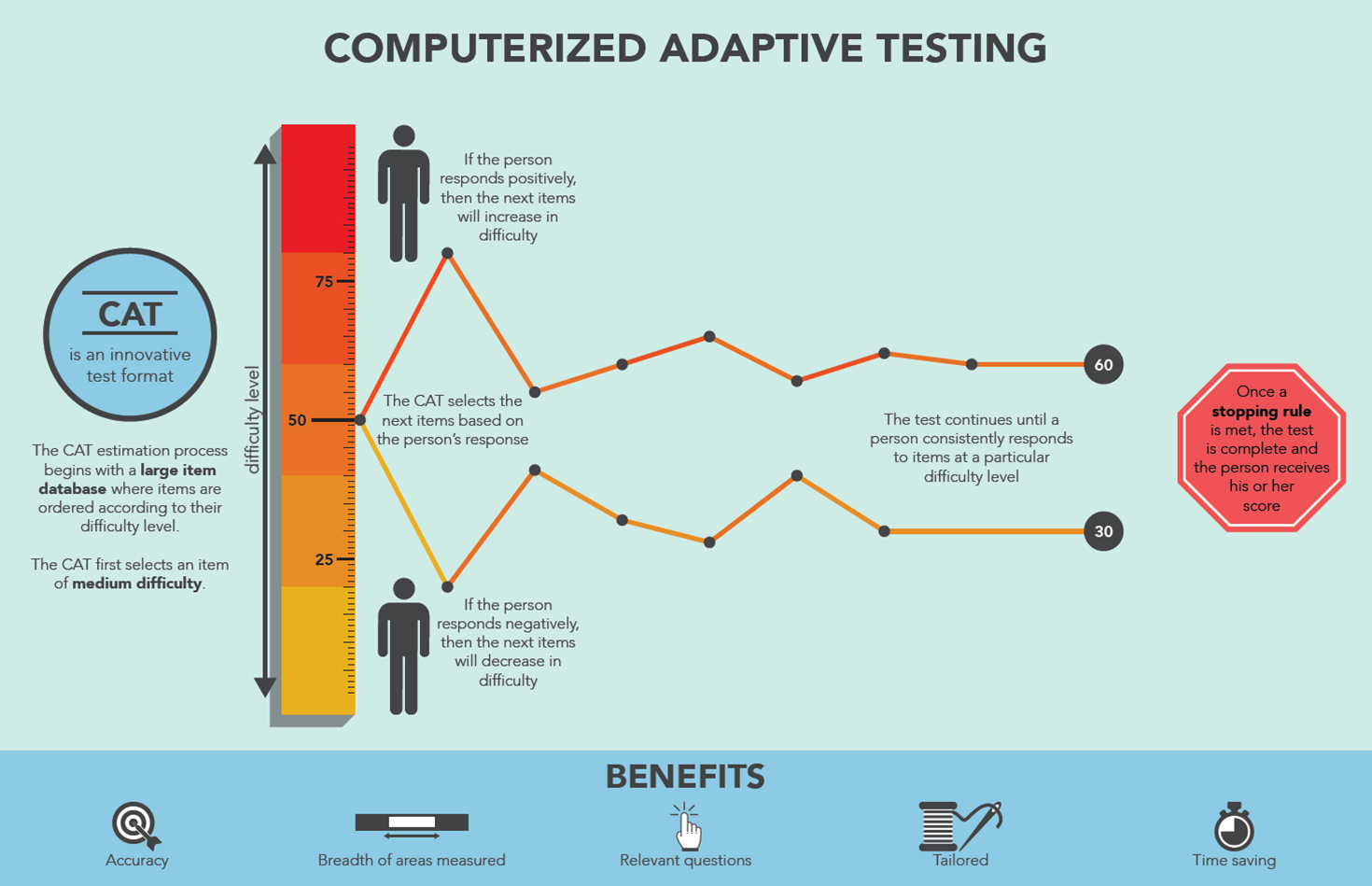
What is CAT?
Computer Adaptive Testing is a method of administering tests where the difficulty of each question adapts in real-time based on the test-taker's ability. Unlike traditional fixed tests where everyone gets the same questions, CAT selects the most informative question for each individual at each step [1][2].
The core idea:
- If you answer correctly → next question is harder
- If you answer incorrectly → next question is easier
- The test converges on your true ability with fewer questions than a fixed test
"CAT yields a high and equal degree of precision for all candidates, and requires fewer items than a conventional test to reach a given degree of precision." — Eggen & Verschoor (2006) [3]
Core Components
1. Item Response Theory (IRT)
IRT is the mathematical foundation of CAT. It models the probability of a correct response as a function of the person's ability and the item's properties [4].
The most common model is the 3-Parameter Logistic (3PL) model:
Where:
- θ (theta) — the person's ability (typically ranges from -3 to +3)
- a — discrimination parameter (how well the item differentiates abilities)
- b — difficulty parameter (the ability level where P = 0.5)
- c — guessing parameter (probability of correct answer by chance)
Simpler models [4]:
- 1PL (Rasch) — only difficulty b, assumes equal discrimination
- 2PL — difficulty b + discrimination a, no guessing
- 3PL — full model with guessing c
2. Item Parameters
Each item in your item bank has parameters that describe its characteristics [4][5]:
Difficulty (b)
- Ranges typically from -3 to +3
- b = -2 → very easy item (most people get it right)
- b = 0 → medium item (50% chance at average ability)
- b = +2 → very hard item (only high ability people get it right)
Discrimination (a)
- Ranges typically from 0 to 3
- Higher a = better at separating high vs low ability test-takers
- a < 0.5 → poor discrimination, item barely helps
- a = 1.0 → good discrimination
- a > 2.0 → excellent discrimination
Guessing (c)
- Ranges from 0 to 1
- For multiple choice with 4 options, c ≈ 0.25
- Accounts for the fact that low-ability test-takers can guess correctly
3. Item Information Function (IIF)
The information an item provides tells us how useful it is for estimating ability at a given theta level [4]:
Key insight:
- An item provides maximum information when its difficulty matches the person's ability (b ≈ θ)
- Items that are too easy or too hard provide little information
- Higher discrimination a = more information overall
This is why CAT selects items where difficulty ≈ current theta — it's the point of maximum information [5].
4. Theta Estimation
After each response, the person's ability estimate is updated. The main methods are [4][6]:
Maximum Likelihood Estimation (MLE)
Finds the theta that maximizes the likelihood of the observed response pattern:
Where u = 1 if correct, u = 0 if incorrect.
Problem: MLE is undefined if all answers are correct or all incorrect.
Bayesian Estimation (EAP/MAP)
Uses a prior distribution (usually normal) combined with the likelihood [6]:
- EAP (Expected A Posteriori) — takes the mean of the posterior
- MAP (Maximum A Posteriori) — takes the mode of the posterior
Bayesian methods work even with all-correct or all-incorrect patterns, making them preferred for CAT [3][6].
Simple Approximation
if correct: theta = theta + 0.3
if incorrect: theta = theta - 0.3This is a simplified approximation — not true IRT but easy to implement for prototyping.
5. Item Selection Methods
At each step, CAT must choose the next best item. Common methods [2][5]:
Maximum Information (most common)
Select the item that provides maximum information at current theta:
# Select item with highest information at current theta
I <- a^2 * P * (1-P) # simplified 2PL information
next_item <- item with max(I)Closest Difficulty (simplified)
Select item whose difficulty is closest to current theta:
items$diff <- abs(items$difficulty - theta)
selected <- items[which.min(items$diff), ]Simple but effective approximation of maximum information.
Other Methods
6. Stopping Rules
CAT stops when one of these conditions is met [3][7]:
| Rule | Description |
|---|---|
| Fixed length | Stop after N items (simplest) |
| Standard error | Stop when SE(θ) < threshold (e.g. SE < 0.3) |
| Confidence interval | Stop when CI is narrow enough |
| Time limit | Stop after time expires |
| Item bank exhausted | No more unused items available |
Standard error of theta:
The more items answered, the lower the SE and the more precise the estimate.
For example, Huda et al. (2024) used SE ≤ 0.01 as the stopping criterion in their CAT implementation for student assessment [7].
Full CAT Process Flow
1. START
θ₀ = 0 (or prior mean)
SE = ∞
2. ITEM SELECTION
Find item i* = argmax I(θ_current)
from unused items
3. PRESENT ITEM
Show question to test-taker
Record response u (1=correct, 0=incorrect)
4. THETA UPDATE
Update θ using MLE or Bayesian method
based on all responses so far
5. STOPPING CHECK
If stopping rule met → go to 6
Else → go back to 2
6. REPORT
Final θ estimate
SE(θ)
Confidence intervalWhy CAT is Better Than Fixed Tests
| Feature | Fixed Test | CAT |
|---|---|---|
| Number of items | Same for everyone (e.g. 50) | Fewer needed (e.g. 20–25) [1] |
| Precision | Same for all ability levels | Highest where it matters [3] |
| Test experience | Many items too easy or too hard | Most items appropriately challenging [2] |
| Item exposure | All items used equally | Risk of overexposure [2] |
| Security | All items known | Items protected by adaptive selection [1] |
| Test time | Longer | Shorter (30–50% reduction) [1] |
Interpreting Theta (θ)
Theta follows a standard normal distribution. Here's how to interpret the score [4]:
| Theta Range | Interpretation |
|---|---|
| θ > 2.0 | Exceptionally high ability |
| 1.0 < θ ≤ 2.0 | High ability |
| -1.0 < θ ≤ 1.0 | Average ability |
| -2.0 < θ ≤ -1.0 | Below average ability |
| θ ≤ -2.0 | Very low ability |
Theta can also be converted to a more familiar scale:
Summary Table
| Concept | Symbol | What it does |
|---|---|---|
| Ability estimate | θ (theta) | Represents person's latent ability [4] |
| Difficulty | b | Item's difficulty level [4] |
| Discrimination | a | How well item separates abilities [4] |
| Guessing | c | Chance of correct answer without knowledge [4] |
| Item Information | I(θ) | How useful an item is at a given theta [5] |
| Standard Error | SE(θ) | Precision of the theta estimate [3] |
| Theta estimation | MLE/EAP | Updates ability after each response [6] |
| Item selection | argmax I(θ) | Picks most informative next item [2] |
| Stopping rule | SE < 0.3 or N items | Decides when test is precise enough [3] |
Key Takeaway
The goal of CAT is always: estimate theta as accurately as possible using as few items as possible [1][3].
CAT achieves this by always asking the question that provides the most information about the person's ability at their current estimated level — making every question count.
References
[1] Davey, T. (2011). A guide to computer adaptive testing systems. Council of Chief State School Officers.
[2] van der Linden, W. J., & Glas, C. A. W. (2022). Computerized Adaptive Testing: Theory and Practice. Kluwer Academic Publishers.
[3] Eggen, T. J. H. M., & Verschoor, A. J. (2006). Overview and current management of computerized adaptive testing in licensing/certification examinations. PMC, NCBI. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5676016/
[4] Lord, F. M. (1980). Applications of Item Response Theory to Practical Testing Problems. Lawrence Erlbaum Associates / Routledge. https://doi.org/10.4324/9780203056615
[5] De Ayala, R. J. (2009). The Theory and Practice of Item Response Theory. New York: The Guilford Press.
[6] Magis, D., & Barrada, J. R. (2017). Computerized Adaptive Testing with R: Recent Updates of the Package catR. Journal of Statistical Software, Code Snippets, 76(1), 1–18. https://doi.org/10.18637/jss.v076.c01
[7] Huda, A., Firdaus, F., Irfan, D., Hendriyani, Y., Almasri, A., & Sukmawati, M. (2024). Optimizing Educational Assessment: The Practicality of Computer Adaptive Testing (CAT) with an Item Response Theory (IRT) Approach. JOIV: International Journal on Informatics Visualization, 8(1), 473–480. https://doi.org/10.62527/joiv.8.1.2217
[8] Magis, D., & Raiche, G. (2012). Random Generation of Response Patterns under Computerized Adaptive Testing with the R Package catR. Journal of Statistical Software, 48(8), 1–31. https://doi.org/10.18637/jss.v048.i08