The Actual Procedure and Process of Computer Adaptive Testing (CAT)
Thumbnail Credit
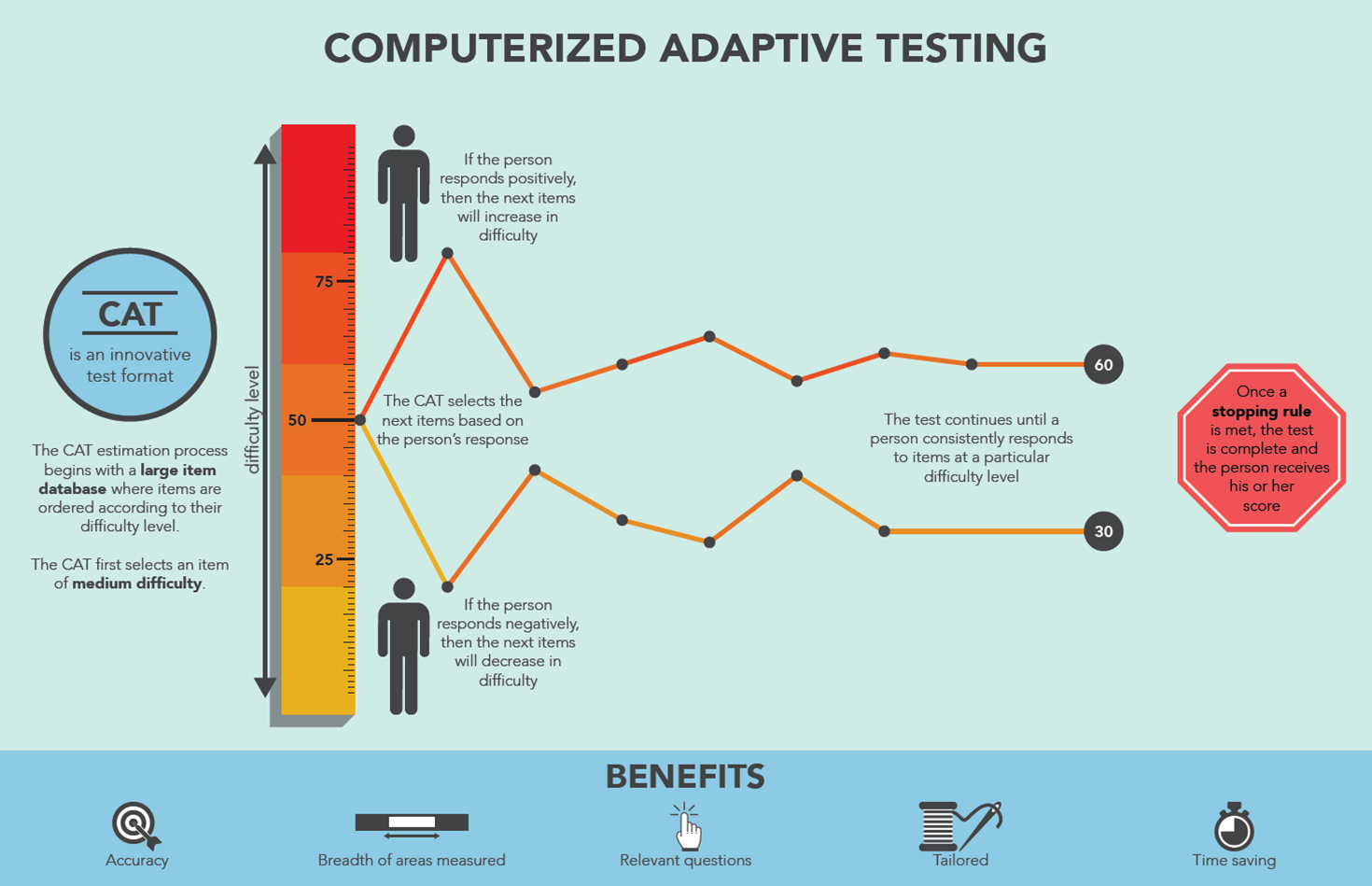
Overview
Computerized Adaptive Testing (CAT) is a form of computer-based testing that adapts in real-time to each test-taker's ability level. According to Weiss (IACAT), its objective is "to select, for each examinee, the set of test questions from a pre-calibrated item bank that simultaneously most effectively and efficiently measures that person on the trait" [1].
Unlike conventional fixed-form tests where all examinees answer the same predetermined questions, CAT dynamically selects items based on the test-taker's estimated ability as they progress through the test [2]. The result is a test that is smarter, shorter, fairer, and more precise [3].
Part 1: The Five Implementation Steps
According to Seo (2017), there are five steps for implementing a CAT system [4]:
Step 1 — Determine Feasibility
Before building a CAT, the test program must evaluate whether CAT is appropriate:
- Is there a sufficient volume of test-takers to calibrate items? (Rule of thumb: at least 200–300 per item)
- Is the construct unidimensional (measuring one trait)? IRT-based CAT assumes this
- Is the item bank large enough? (Recommended: at least 3× the intended test length) [3]
- Are there sufficient resources to build and maintain the platform?
If the test volume is very small (e.g., fewer than 100 test-takers per year), it may be impossible to build a usable item bank. It is not unusual for a testing program to start with a fixed-form test and later transition to CAT once the item bank is well established [5].
Step 2 — Establish an Item Bank
The item bank is the foundation of CAT. It must:
- Contain a large pool of pre-calibrated items with known IRT parameters
- Cover the full range of the ability scale (very easy to very hard)
- Be organized with content categories for content balancing
- Items must be pilot-tested on a representative sample before entering the live bank
"You can't just write a few items and subjectively rank them as Easy, Medium, or Hard. Instead, you need to write a large number of items and then pilot them on a representative sample of examinees." [3]
Step 3 — Pretest, Calibrate, and Link Item Parameters
Each item must be statistically calibrated through:
- Pilot testing on real examinees
- IRT calibration — estimating the (discrimination), (difficulty), and (guessing) parameters
- Linking — placing all items on the same IRT scale so they are comparable
This is done through statistical analysis using actual candidate response data [4].
Step 4 — Specify the Five CAT Algorithm Components
The test developer must define all five components of the CAT algorithm (see Part 2 below) [4]:
- Item bank structure
- Starting item/point
- Item selection rule
- Scoring procedure
- Termination criterion
Step 5 — Deploy the CAT
After specifying all components, the CAT is deployed. Ongoing management includes:
- Content balancing
- Item analysis and refreshment
- Standard setting
- Item exposure monitoring
- Item bank updates [4]
Part 2: The Five Core Algorithm Components
Component 1: Item Bank
The item bank is a pool of pre-calibrated items, each with known IRT parameters [4][5].
Key requirements:
- Size: Typically at least 5–10× the test length to allow adequate item selection and exposure control
- Coverage: Items spanning the full difficulty range ()
- Content balance: Items organized by content domain/category
- Parameters: Each item has at minimum a difficulty () parameter; ideally also discrimination () and guessing () for the 3PL model
Component 2: Starting Point
The starting point determines where the test begins on the ability scale. There are three common options [1][3]:
| Option | Description | Use Case |
|---|---|---|
| Fixed value | Everyone starts at (population mean) | Most common for general tests |
| Randomized | Start within a narrow range, e.g., | Improves test security and item exposure |
| Predicted value | Based on prior data or external information | When prior ability estimate is available |
"At the initial stages of a CAT, when only a single item or two has been administered, the next item is usually selected by a step rule — if the first item was answered correctly, the examinee's original theta estimate is increased by some amount (e.g., 0.50); if the first item was answered incorrectly, the original theta estimate is decreased by the same amount." [1]
Component 3: Item Selection Rule (Algorithm)
This is the heart of the CAT. After each response, the algorithm selects the next best item from the unused items in the bank [5].
The item selection process involves three sub-components [5]:
3a. Item Selection Criterion
The most common methods are Maximum Fisher Information and b-Matching [5][6]:
Maximum Fisher Information (most common)
Selects the item providing the highest statistical information at the current ability estimate :
Where is the Item Information Function (IIF) evaluated at , and is the set of already-used items.
For the 3-Parameter Logistic (3PL) model, the IIF is:
Where is the probability of a correct response given by the 3PL model:
b-Matching (difficulty matching)
Selects the item whose difficulty is closest to the current theta estimate:
Simple but effective; does not require full IIF calculation.
Other criteria: -stratification, weighted likelihood, Kullback-Leibler information [5].
3b. Content Balancing
Ensures the test covers required content domains proportionally — not just statistically optimal items. This addresses the concern of educators and subject matter experts who require balanced content coverage [2][5].
3c. Item Exposure Control
Prevents certain items from being administered too frequently, which would compromise test security [5]. Common methods:
- Randomesque method — randomly selects from the top- most informative items
- Sympson-Hetter method — probabilistically suppresses overexposed items
- Fade-away method — gradually reduces exposure of frequently used items
"Selecting the right method for each of the 3 components of the item selection process — content balancing, the item selection criterion, and item exposure control — is not straightforward and cannot be considered separately for each of these 3 components because of the unique interactions among them." [5]
Component 4: Scoring Procedure (Theta Estimation)
After each response, the test-taker's ability estimate is updated [2][6].
The scoring algorithm takes all previous responses into account — not just the most recent one. Let denote the vector of responses where if correct and if incorrect.
Maximum Likelihood Estimation (MLE)
Finds the that maximizes the likelihood of the observed response pattern:
The likelihood function is:
In practice, the log-likelihood is maximized:
- Pro: Unbiased estimate
- Con: Undefined when all responses are correct or all incorrect [1]
Bayesian EAP (Expected A Posteriori)
Combines the likelihood with a prior distribution (typically standard normal ):
- Pro: Works even with all-correct or all-incorrect response patterns
- Pro: Provides a natural standard error estimate
- Con: Slightly biased toward the prior mean in early items [6]
Bayesian MAP (Maximum A Posteriori)
Takes the mode of the posterior distribution:
Intermediate between MLE and EAP in terms of bias and variance.
"The algorithm then selects the most informative item from the calibrated item bank based on this estimate. After the examinee responds, the ability estimate is updated using maximum likelihood or Bayesian methods, and the cycle continues until a stopping criterion is met." [6]
Standard Error of Measurement (SEM)
The precision of the theta estimate is tracked via the Test Information Function:
The Standard Error of Measurement is:
The SEM decreases as more items are administered. CAT continues until falls below a specified threshold.
Component 5: Termination Criterion
The stopping rule decides when to end the test. Common criteria [2][4][6]:
| Criterion | Condition | Advantage |
|---|---|---|
| Fixed length | Stop after items | Simple, equal testing time |
| Fixed precision | Stop when | Precision-based; adaptive length |
| Combined | Stop when OR | Balances precision and efficiency |
| Classification | Stop when ability is clearly above/below a cut score | Used in pass/fail exams (e.g., NCLEX) |
| Time limit | Stop after maximum time | Practical constraint |
For classification-based stopping (e.g., pass/fail), the decision rule is:
Where is the passing cut score and is the critical value at significance level .
"Fixed-length tests administer a predetermined number of items, while precision-based stopping continues until the standard error of measurement falls below a threshold." [6]
For high-stakes exams like the NCLEX:
"This pattern continues until you run out of time or until the computer identifies your competency level as above or below the passing standard." [7]
Part 3: The Full CAT Runtime Process
Once deployed, the following iterative process runs for each test-taker [2][33]:
Part 4: IRT Models Used in CAT
CAT is built on Item Response Theory. The three most common models are [10]:
1PL — Rasch Model
Only difficulty varies between items; discrimination is fixed at and guessing :
2PL Model
Both difficulty and discrimination vary; no guessing ():
3PL Model (most common in high-stakes CAT)
All three parameters vary — discrimination , difficulty , and guessing :
Where:
- , typically — test-taker ability
- — item discrimination (steepness of the curve)
- — item difficulty (location of the curve)
- — pseudo-guessing parameter (lower asymptote)
Part 5: Historical Origins
The adaptive testing concept is not new. Its origins can be traced to Alfred Binet's IQ test (1905), which used an adaptive procedure: items were organized by age-difficulty level, and the examiner would probe upward or downward based on each child's responses [1].
The key historical milestones are [1][8]:
| Year | Event |
|---|---|
| 1905 | Binet's adaptive IQ test — first adaptive testing procedure |
| 1952 | Lord observes that ability scores are test-independent (unlike observed scores) |
| 1960 | Rasch describes the one-parameter logistic IRT model |
| 1973 | Weiss proposes the "stradaptive" computer-delivered test |
| 1980 | Lord publishes the foundational IRT textbook |
| 1994 | NCLEX (nursing licensure exam) adopts CAT — first large-scale operational use |
| 2007 | National Registry of Emergency Medical Technicians adopts CAT |
Part 6: Practical Example — How CAT Selects Items
The following example illustrates the item selection process step by step [3]:
Suppose we have five items in the bank and the starting theta is .
Round 1:
- Compute for all items → Item 4 has highest information
- Test-taker answers incorrectly ()
- Run MLE/EAP → new estimate:
- Check termination: too large, continue
Round 2:
- Compute for remaining items → Item 2 has highest information
- Test-taker answers correctly ()
- Update theta →
- Check termination: not done yet
Round 3:
- Item 2 and Item 4 already used ()
- Next best available at → Item 1
- Test-taker answers correctly (, item is easy)
- Update theta →
- Continue...
This demonstrates how CAT homes in on the test-taker's true ability through successive approximation.
Part 7: Advantages and Challenges
Advantages
| Advantage | Detail |
|---|---|
| Efficiency | Typically 50% fewer items needed for same precision |
| Equal precision | is controlled uniformly across all ability levels |
| Fairness | Each test-taker gets items appropriate to their level |
| Immediate results | Scoring is done in real-time |
| Security | Unique item sets make sharing answers less useful |
| Adaptive length | Test ends when |
Challenges
| Challenge | Detail |
|---|---|
| Item bank development | Requires large pilot studies to calibrate , , parameters |
| Cost | Expensive to build and maintain the platform |
| Test-taker experience | Test-takers may feel discouraged if items seem consistently hard |
| Content balance | Purely statistical selection (argmax ) may neglect content coverage |
| Item exposure | Items with high at common values are overused |
| Unidimensionality | IRT assumes a single latent trait ; multidimensional constructs are harder |
"A trade-off must be made between the psychological experiences of test-takers and measurement efficiency." [2]
Part 8: Real-World Applications
CAT is used in many high-stakes assessments worldwide [1][4]:
| Exam | Domain | CAT Since |
|---|---|---|
| NCLEX-RN / NCLEX-PN | Nursing licensure (USA) | 1994 |
| GRE General Test | Graduate school admissions | 1994 |
| GMAT | Business school admissions | 1997 |
| NREMT | Emergency Medical Technicians | 2007 |
| TOEFL iBT | English language proficiency | adaptive sections |
| ASVAB-CAT | US Military enlistment | adaptive version |
Summary
The CAT process can be summarized in three phases:
Before the test (Development):
- Determine feasibility
- Write and pilot items
- Calibrate IRT parameters (, , )
- Build and validate the item bank
- Define all five algorithm components
During the test (Runtime loop):
- Set starting point
- Select from unused items
- Administer item, record response
- Update using MLE or EAP; compute
- Check stopping rule → repeat or stop
After the test (Reporting):
- Report final and
- Apply score transformation if needed
- Log responses for item bank maintenance
References
[1] Weiss, D. J. (n.d.). Introduction to CAT. International Association for Computerized Adaptive Testing (IACAT). https://iacat.org/introduction-to-cat/
[2] Kim, J., & Chung, H. (2017). The impacts of computer adaptive testing from a variety of perspectives. PMC. https://pmc.ncbi.nlm.nih.gov/articles/PMC5549015/
[3] Assessment Systems Corporation. (2025). Computerized Adaptive Testing (CAT): Software, Meaning, Example. https://assess.com/computerized-adaptive-testing/
[4] Seo, D. G. (2017). Overview and current management of computerized adaptive testing in licensing/certification examinations. Journal of Educational Evaluation for Health Professions, 14, 17. https://doi.org/10.3352/jeehp.2017.14.17
[5] Kim, D., & Chung, H. (2018). Components of the item selection algorithm in computerized adaptive testing. Journal of Educational Evaluation for Health Professions. https://pmc.ncbi.nlm.nih.gov/articles/PMC5968224/
[6] Cogn-IQ. (2026). Adaptive Testing in Psychometrics — Definition & Examples. https://www.cogn-iq.org/learn/theory/adaptive-testing/
[7] UWorld Nursing. (2025). What Is NCLEX Computerized Adaptive Testing (CAT)? https://nursing.uworld.com/blog/nclex-computer-adaptive-test/
[8] Janssen, R., & De Boeck, P. (2010). Computerized adaptive testing: implementation issues. arXiv. https://arxiv.org/pdf/1012.0042
[9] Wikipedia contributors. (2026). Computerized adaptive testing. Wikipedia. https://en.wikipedia.org/wiki/Computerized_adaptive_testing
[10] Lord, F. M. (1980). Applications of Item Response Theory to Practical Testing Problems. Lawrence Erlbaum Associates.